Bạn đang thắc mắc robots.txt là gì và tại sao robots.txt lại quan trọng trong chiến lược SEO? Đây chính là tệp tin nhỏ nhưng có quyền lực lớn, giúp bạn kiểm soát cách các công cụ tìm kiếm thu thập dữ liệu trên website. Trong bài viết này, cùng Cyno Software tìm hiểu chi tiết về file robot txt là gì, cách tạo và gửi robots.txt đúng chuẩn SEO 2025 để tăng khả năng hiển thị và xếp hạng trên Google.

File robots.txt là gì?
File robots.txt là một tệp văn bản dạng .txt, được đặt tại thư mục gốc của website, dùng để hướng dẫn các công cụ tìm kiếm như Googlebot về cách thu thập dữ liệu trên trang web. Tệp này giúp xác định rõ phần nào của website được phép truy cập và phần nào cần hạn chế, từ đó kiểm soát tốt hơn quá trình lập chỉ mục.
>>> Xem thêm: Tăng Thứ Hạng Google Với Dịch Vụ SEO Chất Lượng
Mục đích sử dụng chính của robots.txt là kiểm soát quyền truy cập của bot đến các khu vực nhất định như trang quản trị, giỏ hàng, trang tìm kiếm nội bộ hay nội dung trùng lặp. Robots.txt cũng cho phép bạn chỉ định vị trí của file sitemap.xml và thiết lập crawl-delay để giới hạn tần suất truy cập của bot, tránh gây quá tải cho máy chủ.
Trong SEO, robots.txt đóng vai trò quan trọng khi giúp công cụ tìm kiếm tập trung vào các trang có giá trị, cải thiện hiệu quả thu thập dữ liệu và tăng tốc độ lập chỉ mục. Nhờ đó, thứ hạng của website trên kết quả tìm kiếm có thể được cải thiện đáng kể.

File robots.txt hoạt động như thế nào?
Các công cụ tìm kiếm như Google có hai nhiệm vụ chính: crawl (thu thập dữ liệu) và index (lập chỉ mục) nội dung để phục vụ truy vấn tìm kiếm của người dùng. Khi bot của công cụ tìm kiếm truy cập một website, việc đầu tiên bot làm là tìm và đọc file robots.txt nếu tệp này tồn tại ở thư mục gốc.
File robots.txt là tập tin hướng dẫn bot về khu vực nào trên website được phép hoặc không được phép thu thập dữ liệu. Các chỉ thị như User-agent, Disallow, Allow giúp bot tuân thủ quy tắc khi thu thập. Nếu không có robots.txt hoặc không có hướng dẫn, bot như Semrush là gì sẽ mặc định thu thập toàn bộ nội dung có thể truy cập.
Tác động của robots.txt là rất rõ ràng, robots.txt điều hướng hành vi của bot, giúp tiết kiệm tài nguyên crawl, ngăn lập chỉ mục các trang không cần thiết và tối ưu quá trình hiển thị nội dung trên kết quả tìm kiếm.

Cú pháp và cấu trúc của file robots.txt
Để file robots.txt phát huy đúng vai trò kiểm soát bot, bạn cần nắm rõ cú pháp và cách cấu trúc chuẩn của tệp này.
Cú pháp phổ biến
Trong file robots.txt, có một số cú pháp cơ bản và phổ biến mà bạn cần biết để điều khiển cách các bot tìm kiếm thu thập dữ liệu trên website.
- User-agent: Đây là tên của các trình thu thập dữ liệu web (web crawler), như Googlebot, Bingbot,… Dòng này xác định bot nào sẽ áp dụng các quy tắc tiếp theo trong file robots.txt.
- Disallow: Dùng để chỉ định các URL hoặc thư mục mà bot không được phép truy cập hoặc thu thập dữ liệu. Mỗi URL hoặc thư mục cần chặn được ghi trên một dòng Disallow riêng biệt. Ví dụ, Disallow: /admin sẽ ngăn bot truy cập vào thư mục admin.
- Allow: Chỉ áp dụng cho Googlebot, lệnh này cho phép truy cập vào một trang hoặc thư mục con, ngay cả khi thư mục cha bị chặn bởi lệnh Disallow. Điều này giúp bạn có thể linh hoạt kiểm soát bot truy cập vào những phần cụ thể của website.
- Crawl-delay: Yêu cầu bot tạm dừng trong một khoảng thời gian nhất định (tính bằng giây) trước khi tải trang tiếp theo, nhằm giảm tải cho máy chủ khi có nhiều bot cùng thu thập dữ liệu. Tuy nhiên, Googlebot không hỗ trợ lệnh này, và bạn cần điều chỉnh tốc độ thu thập qua Google Search Console nếu muốn.
- Sitemap: Dùng để khai báo vị trí của các file Sitemap XML liên kết với website, giúp bot nhanh chóng nhận biết cấu trúc trang và thu thập dữ liệu hiệu quả hơn. Lệnh này được hỗ trợ bởi các công cụ tìm kiếm lớn như Google, Bing, Yahoo và Ask.
Pattern – Matching
File robots.txt cho phép sử dụng Pattern Matching để kiểm soát chi tiết hơn việc truy cập của các bot đến nhiều URL cùng lúc, thay vì phải liệt kê từng đường dẫn cụ thể. Đây là một tính năng rất hữu ích, đặc biệt khi website có nhiều trang hoặc thư mục con cần chặn hoặc cho phép cùng lúc. Hai ký tự đại diện phổ biến được hỗ trợ bởi Google và Bing trong robots.txt là:
- Dấu hoa thị (*): Đại diện cho bất kỳ chuỗi ký tự nào, cho phép bao quát nhiều URL có chung phần đầu hoặc giữa. Ví dụ, Disallow: /private/* sẽ chặn tất cả các URL bắt đầu bằng /private/ dù phần sau có gì đi nữa.
- Ký hiệu đô la ($): Đại diện cho phần kết thúc của URL, giúp chỉ định chính xác các URL kết thúc theo một mẫu nhất định. Ví dụ, Disallow: /*.pdf$ sẽ ngăn bot truy cập tất cả các tập tin có đuôi .pdf.

Định dạng cơ bản của file robots.txt
File robots.txt được xây dựng dựa trên nguyên tắc nhóm các quy tắc cho từng loại bot cụ thể. Mỗi nhóm bao gồm ít nhất hai dòng lệnh:
- User-agent: chỉ định tên bot mà nhóm quy tắc này áp dụng.
- Disallow/Allow: quy định bot được hoặc không được phép truy cập các thư mục hoặc trang cụ thể.
Internal là gì? Trong file robots.txt, các dòng lệnh trong cùng một nhóm (internal group) được viết liền nhau, cách nhau bởi một dòng trống để phân biệt nhóm này với nhóm khác. Một file robots.txt có thể có nhiều nhóm User-agent khác nhau để kiểm soát truy cập. Bạn có thể bỏ qua lệnh như Crawl-delay hoặc Sitemap nếu không cần, vì không phải bot nào cũng hỗ trợ chúng.
Mẫu chuẩn file robots.txt thường rất đơn giản và phổ biến như:
- Chặn toàn bộ bot không được phép thu thập bất cứ dữ liệu nào trên website:
User-agent: * Disallow: /
- Cho phép tất cả bot truy cập toàn bộ website:
User-agent: * Disallow:
- Chặn một bot cụ thể (ví dụ Googlebot) không được thu thập dữ liệu trong thư mục con:
User-agent: Googlebot Disallow: /private-folder/

Ví dụ minh họa cụ thể cho file robots.txt:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php Sitemap: https://www.example.com/sitemap.xml
Ví dụ: Giả sử website của bạn có thư mục quản trị /wp-admin/ cần bảo vệ, nhưng vẫn muốn cho bot truy cập file admin-ajax.php bên trong đó, đồng thời cung cấp link sitemap để các công cụ tìm kiếm dễ dàng thu thập dữ liệu.
File robots.txt có thể viết như sau:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php Sitemap: https://www.example.com/sitemap_index.xml
Giải thích:
- Tất cả các bot đều bị cấm truy cập vào thư mục /wp-admin/ để bảo mật.
- Nhưng Googlebot và các bot hỗ trợ Allow được phép truy cập file admin-ajax.php trong thư mục này.
- Lệnh Sitemap giúp bot tìm đến sơ đồ website, tăng hiệu quả lập chỉ mục.
Vị trí và cách kiểm tra file robots.txt
File robots.txt bắt buộc phải được đặt ở thư mục gốc (root directory) của website, tức là ngay tại cấp cao nhất của tên miền chính. Ví dụ, nếu website của bạn là https://www.example.com, thì file robots.txt phải nằm ở địa chỉ: https://www.example.com/robots.txt
Để kiểm tra nhanh website của bạn hoặc bất kỳ website nào đã có file robots.txt chưa, bạn chỉ cần nhập URL sau vào trình duyệt: https://www.tendomain.com/robots.txt

Nếu website có file robots.txt, bạn sẽ thấy nội dung dưới dạng văn bản thuần khi truy cập, còn nếu không, trình duyệt sẽ báo lỗi 404, nghĩa là website chưa có file này. Bạn có thể kiểm tra thủ công hoặc dùng công cụ để xác định tính hợp lệ và hoạt động của file robots.txt. Ngoài ra, trong SEO, topic cluster là gì được hiểu là phương pháp tổ chức nội dung theo nhóm chủ đề liên quan, giúp tăng cường liên kết giữa các bài viết và cải thiện thứ hạng tìm kiếm hiệu quả hơn.
- Google Search Console: Có công cụ “Kiểm tra robots.txt” giúp bạn xem Googlebot có thể truy cập hay bị chặn trang nào trên website không. Công cụ này còn giúp phát hiện lỗi cú pháp hoặc xung đột trong file robots.txt.
- Các công cụ trực tuyến khác: Có nhiều website cung cấp dịch vụ kiểm tra file robots.txt miễn phí như SEOBook, Robots.txt Checker,… giúp bạn phân tích và đưa ra cảnh báo chi tiết.
Hướng dẫn tạo file robots.txt
Hướng dẫn tạo file robot txt đơn giản dưới đây giúp bạn quản lý việc thu thập dữ liệu các công cụ tìm kiếm hiệu quả.
Tạo file robots.txt thủ công
Dưới đây là hướng dẫn chi tiết cách tạo và triển khai tệp robots.txt thủ công cho website của bạn:
Bước 1: Tạo tệp robots.txt
Sử dụng các trình soạn thảo văn bản như Notepad, TextEdit, vi hoặc emacs để tạo file. Đảm bảo lưu file ở định dạng mã hóa UTF-8 để giữ nguyên chuẩn định dạng.
Bước 2: Đặt tên và vị trí lưu tệp
Tên tệp phải là robots.txt và được lưu trực tiếp tại thư mục gốc của website, ví dụ: https://www.example.com/robots.txt. Lưu ý mỗi website chỉ có thể có một tệp robots.txt và chỉ có hiệu lực trên miền hoặc cổng chứa tệp đó (ví dụ, tệp tại https://example.com/robots.txt không áp dụng cho https://m.example.com/).

Bước 3: Viết các quy tắc trong file
File robots.txt gồm nhiều nhóm quy tắc, mỗi nhóm bắt đầu bằng User-agent để chỉ định bot mục tiêu, kèm theo các lệnh sau:
- User-agent: Xác định bot cần áp dụng quy tắc, dấu * đại diện cho tất cả các bot.
- Disallow: Chặn bot truy cập vào URL hoặc thư mục cụ thể.
- Allow: Cho phép bot truy cập URL cụ thể, ghi đè lên Disallow.
- Sitemap: Chỉ định vị trí file sitemap giúp bot hiểu cấu trúc website.
Ví dụ về quy tắc:
- Chặn tất cả bot truy cập toàn bộ website:
User-agent: * Disallow: /
- Chặn Googlebot truy cập thư mục /private/:
User-agent: Googlebot Disallow: /private/
Bước 4: Tải file lên server
Sau khi hoàn tất, upload file robot txt lên thư mục gốc của website qua FTP hoặc trình quản lý file của hosting. Nếu không có quyền truy cập, liên hệ nhà cung cấp dịch vụ hosting để được hỗ trợ.
Bước 5: Kiểm tra và gửi file cho Google
Truy cập https://example.com/robots.txt để kiểm tra file đã được tải lên chính xác. Sử dụng công cụ kiểm tra robots.txt trên Google Search Console để xác nhận cấu hình. Google sẽ tự động nhận diện file, nhưng bạn cũng có thể yêu cầu cập nhật thủ công qua Google Search Console để làm mới nhanh hơn.
Tạo file robots.txt cho WordPress
Việc tạo file robot txt cho WordPress có thể thực hiện dễ dàng bằng nhiều cách khác nhau. Dưới đây là 3 phương pháp phổ biến giúp bạn nhanh chóng thiết lập robot txt file chuẩn chỉnh cho website của mình.

Sử dụng Yoast SEO
Yoast SEO là một plugin SEO rất phổ biến cho WordPress và hỗ trợ tạo, chỉnh sửa file robots.txt ngay trong bảng điều khiển WordPress:
- Vào SEO → Công cụ trong bảng điều khiển WordPress.
- Chọn mục Trình chỉnh sửa tệp (File editor).
- Tại đây bạn có thể tạo mới hoặc chỉnh sửa trực tiếp file robots.txt hiện có.
- Sau khi chỉnh sửa, nhấn Lưu thay đổi để cập nhật file robots.txt trên website.
- Đây là cách đơn giản và nhanh chóng, không cần phải truy cập máy chủ hay FTP.
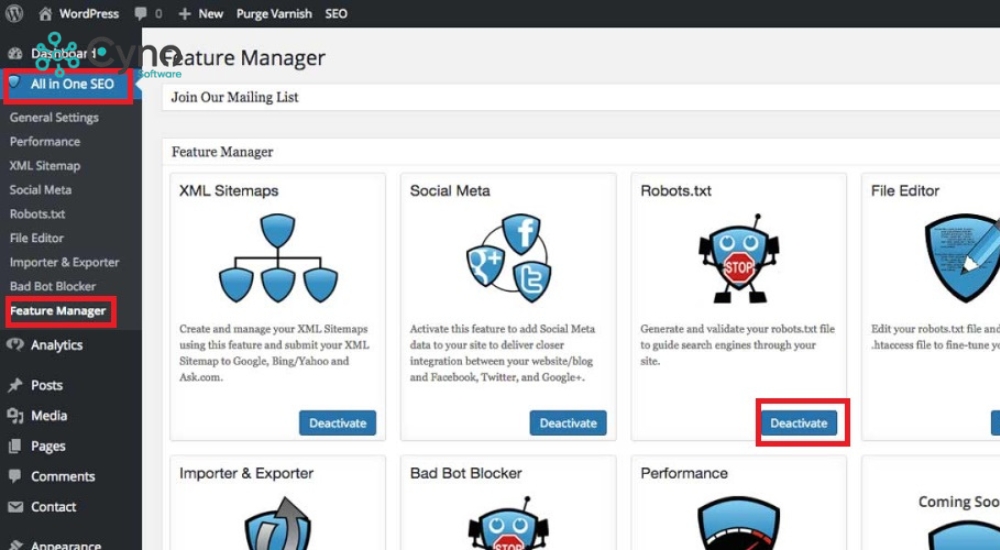
Sử dụng Plugin All in One SEO
All in One SEO cũng là một plugin SEO rất mạnh mẽ và dễ dùng, hỗ trợ tạo file robots.txt:
- Cài đặt và kích hoạt plugin All in One SEO.
- Vào phần All in One SEO → Cài đặt Công cụ (Tools).
- Tại tab File Editor, bạn sẽ thấy khu vực để chỉnh sửa file robots.txt hoặc tạo mới nếu chưa có.
- Chỉnh sửa nội dung theo ý muốn rồi nhấn lưu để cập nhật.
- Phương pháp này tiện lợi cho người không quen thao tác với FTP hay máy chủ.
Upload file robots.txt thủ công qua FTP
Nếu bạn muốn kiểm soát hoàn toàn file robots.txt hoặc website chưa có file, bạn có thể tạo file thủ công và upload lên server qua FTP:
- Tạo file robots.txt trên máy tính bằng trình soạn thảo văn bản (Notepad, TextEdit…) với định dạng UTF-8.
- Viết các quy tắc theo cú pháp robots.txt.
- Sử dụng phần mềm FTP (ví dụ FileZilla) kết nối vào máy chủ lưu trữ website.
- Upload robot txt file lên thư mục gốc của website (thư mục chứa file index.php hoặc index.html).
- Sau đó truy cập https://yourdomain.com/robots.txt để kiểm tra file đã hoạt động hay chưa.
Cách gửi file robots.txt lên Google và công cụ tìm kiếm
Sau khi tạo và cập nhật file robots.txt, bước tiếp theo quan trọng là gửi tệp này đến Google và các công cụ tìm kiếm để đảm bảo chúng đọc được các quy tắc mà bạn đã thiết lập. Dưới đây là các bước thực hiện:
Google sẽ tự động thu thập và đọc file robots.txt của bạn nếu file được đặt đúng tại thư mục gốc (ví dụ: https://www.example.com/robots.txt). Tuy nhiên, để tăng tốc độ cập nhật hoặc kiểm tra tính hợp lệ, bạn có thể chủ động gửi file qua Google Search Console:

- Truy cập vào tài khoản Google Search Console.
- Chọn thuộc tính (property) website bạn cần quản lý.
- Trong thanh công cụ bên trái, chọn Cài đặt (Settings) → Công cụ kiểm tra URL (URL Inspection Tool).
- Nhập URL file robots.txt (ví dụ: https://www.example.com/robots.txt), nhấn Enter.
- Google sẽ hiển thị bản xem trước file và tình trạng đọc file.
- Nhấn nút Gửi yêu cầu lập chỉ mục (Request Indexing) để thông báo Google kiểm tra lại file này sớm nhất.
Để biết Google hoặc các bot có đang đọc đúng file robots.txt của bạn không, bạn có thể thực hiện một số cách sau:
- Truy cập trực tiếp đường dẫn https://www.tenmiencuaban.com/robots.txt trên trình duyệt để xem nội dung tệp có hiển thị đúng hay không.
- Dùng các công cụ bên ngoài như: robots.txt Checker by Ryte, SEO Site Checkup
- Theo dõi Log Server hoặc dùng Googlebot IP để kiểm tra xem Google có request file robots.txt không.
Những quy tắc quan trọng cần có trong robots.txt WordPress
Robots txt file đóng vai trò định hướng các trình thu thập dữ liệu (bot) của công cụ tìm kiếm khi truy cập website. Đối với WordPress, việc xây dựng một file robots.txt hiệu quả không chỉ giúp tăng hiệu suất thu thập dữ liệu mà còn cải thiện trải nghiệm người dùng và bảo mật. Dưới đây là các quy tắc bạn nên lưu ý:

- Để tránh lãng phí ngân sách thu thập dữ liệu (crawl budget) vào những phần không mang lại giá trị SEO, bạn nên chặn các đường dẫn kỹ thuật hoặc dư thừa.
- Tuyệt đối không chặn thư mục /wp-content/themes/ hoặc /wp-content/plugins/ vì điều này có thể ngăn bot đọc các file CSS, JS và ảnh hưởng đến cách hiển thị trang web trên kết quả tìm kiếm.
- Để website được hiển thị chính xác, hãy đảm bảo các tài nguyên như ảnh, tệp CSS và JavaScript vẫn được phép truy cập.
- Ở cuối file robots.txt, bạn nên thêm đường dẫn tới tệp sitemap để các công cụ tìm kiếm nhanh chóng tìm thấy và hiểu cấu trúc nội dung của website: Sitemap: https://www.example.com/sitemap_index.xml
- Tên file phải là robots.txt (chữ thường hoàn toàn), vì hệ thống phân biệt chữ hoa – chữ thường.
- File phải được đặt ở thư mục gốc của website.
- File robots.txt là công khai, ai cũng có thể truy cập bằng cách thêm /robots.txt vào cuối tên miền.
- Một số bot độc hại hoặc spam bot có thể bỏ qua quy tắc trong robots.txt, vì vậy không nên dùng tệp này để ẩn dữ liệu cá nhân hoặc thông tin nhạy cảm.
Tác động của robots.txt đến các loại tệp
Tệp robots.txt là công cụ kiểm soát quyền truy cập của bot tìm kiếm đến các phần khác nhau của website. Tùy thuộc vào loại tệp, robots.txt có thể ảnh hưởng đến khả năng lập chỉ mục và hiển thị nội dung trên kết quả tìm kiếm. Dưới đây là tác động cụ thể đến từng loại tệp:

- Đối với các trang HTML: Phần nội dung chính của website nếu bị chặn bởi robots.txt, bot sẽ không thể thu thập hoặc lập chỉ mục nội dung của trang đó. Điều này có nghĩa là trang sẽ không xuất hiện trên kết quả tìm kiếm. Vì vậy, chỉ nên chặn những trang kỹ thuật, không mang lại giá trị SEO như trang quản trị, kết quả tìm kiếm nội bộ,…
- Tệp đa phương tiện: hình ảnh, video: Bạn có thể sử dụng robots.txt để ngăn công cụ tìm kiếm lập chỉ mục hình ảnh, video nếu muốn bảo vệ bản quyền hoặc tiết kiệm tài nguyên máy chủ. Tuy nhiên, điều này đồng nghĩa với việc các tệp này sẽ không xuất hiện trên Google hình ảnh hoặc video, gây ảnh hưởng đến lượng truy cập từ kênh tìm kiếm đa phương tiện.
- Tệp tài nguyên CSS, JavaScript: Việc chặn CSS hoặc JavaScript bằng robots.txt có thể gây ảnh hưởng tiêu cực đến khả năng hiểu trang web của Googlebot. Khi không thể truy cập các tệp này, bot sẽ gặp khó khăn trong việc hiển thị đúng cấu trúc và giao diện của trang, từ đó ảnh hưởng đến đánh giá Trải nghiệm trang (Page Experience) – một yếu tố quan trọng trong SEO hiện đại.
Những hạn chế của robots.txt bạn cần biết
Tệp robots.txt là công cụ phổ biến trong SEO giúp điều hướng hoạt động của các bot tìm kiếm trên website. Tuy nhiên, robots.txt không phải là “tấm khiên toàn năng”. Dưới đây là những hạn chế quan trọng bạn cần nắm rõ khi sử dụng:

- Không chặn hoàn toàn việc index nội dung: Robots.txt chỉ ngăn bot truy cập, không ngăn việc index nếu URL bị liên kết từ nơi khác. Kết quả là trang vẫn có thể xuất hiện trên Google mà không có nội dung hiển thị (chỉ tiêu đề và URL).
- Không bảo mật thông tin: File robots.txt là công khai, bất kỳ ai cũng có thể truy cập bằng cách thêm /robots.txt vào cuối tên miền. Do đó, không nên dùng để ẩn thông tin nhạy cảm hay dữ liệu cá nhân.
- Một số bot không tuân theo robots.txt: Các bot độc hại hoặc bot không đáng tin cậy thường phớt lờ file robots.txt, tiếp tục thu thập dữ liệu trái phép hoặc spam.
- Cú pháp khác nhau ở mỗi công cụ tìm kiếm: Không phải mọi công cụ tìm kiếm đều hỗ trợ đầy đủ các chỉ thị như Crawl-delay, Allow, hoặc cách diễn giải có thể khác nhau, gây sai lệch nếu không kiểm tra kỹ.
Các lỗi thường gặp khi sử dụng robots.txt
Dưới đây là một số lỗi phổ biến khi sử dụng file robots.txt mà người quản trị web thường gặp, ảnh hưởng trực tiếp đến khả năng thu thập và hiển thị dữ liệu trên công cụ tìm kiếm:

- Không đặt file ở thư mục gốc: Nếu robots.txt không nằm trong thư mục gốc (ví dụ: https://example.com/robots.txt), các bot tìm kiếm sẽ không thể đọc được, đồng nghĩa với việc mọi chỉ thị trong file đều bị bỏ qua.
- Lạm dụng ký tự đại diện: Việc dùng sai ký tự * và $ trong cú pháp có thể vô tình chặn toàn bộ website hoặc cho phép truy cập nhầm trang. Hãy kiểm tra kỹ bằng công cụ test robots.txt trước khi áp dụng.
- Dùng lệnh noindex (không còn được hỗ trợ): Google đã ngừng hỗ trợ lệnh noindex trong robots.txt từ năm 2019. Thay vào đó, hãy sử dụng thẻ meta robots hoặc HTTP header x-robots-tag.
- Chặn CSS và JS: Ngăn bot truy cập vào tệp CSS/JS có thể khiến website hiển thị sai trên kết quả tìm kiếm. Nên cho phép truy cập các tài nguyên cần thiết để đảm bảo Google hiểu đúng nội dung trang.
- Thiếu sơ đồ trang (sitemap): Không khai báo URL của sitemap trong robots.txt khiến bot khó thu thập dữ liệu đầy đủ. Hãy thêm dòng Sitemap: https://example.com/sitemap.xml vào cuối file.
- Cho phép index website đang phát triển: Bot lập chỉ mục những nội dung chưa hoàn thiện có thể gây ảnh hưởng xấu đến SEO. Sử dụng Disallow tạm thời và gỡ bỏ khi site chính thức hoạt động.
- Dùng đường dẫn tuyệt đối: Robots.txt nên dùng đường dẫn tương đối (ví dụ: /private/) thay vì URL đầy đủ để tránh gây hiểu nhầm cho các bot tìm kiếm.
- Dùng cú pháp lỗi thời: Một số lệnh như “crawl-delay” hoặc “noindex” không còn được các công cụ tìm kiếm hỗ trợ. Hãy sử dụng các phương pháp kiểm soát hiện đại như meta robots hoặc header.
Câu hỏi thường gặp về file robots.txt
Giải đáp nhanh các câu hỏi thường gặp giúp bạn hiểu rõ hơn về file robots.txt và cách sử dụng hiệu quả.

Robots.txt và sitemap khác nhau như thế nào?
Robots.txt dùng để hướng dẫn bot cách truy cập trang, còn sitemap liệt kê toàn bộ URL giúp bot dễ dàng thu thập dữ liệu hơn.
Có thể dùng nhiều file robots.txt cho một site không?
Mỗi website chỉ được phép có một file robots txt duy nhất đặt ở thư mục gốc của tên miền. Nếu có nhiều hơn, các bot chỉ đọc file robots.txt ở vị trí chuẩn này và bỏ qua các file khác.
Làm sao để chặn toàn bộ bot thu thập dữ liệu?
Bạn có thể chặn toàn bộ bot bằng cách đặt lệnh User-agent: * và Disallow: / trong file robots.txt. Cách này sẽ ngăn mọi bot truy cập và thu thập dữ liệu trên toàn bộ website.

Robots.txt khác gì với Meta robot và X-Robots-Tag?
Robots.txt chỉ định những phần nào của website bot được phép hoặc không được phép truy cập. Meta robot và X-Robots-Tag lại điều khiển việc bot lập chỉ mục, theo dõi hoặc không theo dõi nội dung của trang khi đã truy cập.
Nếu dùng Disallow với nội dung Noindex thì có sao không?
Nếu bạn dùng Disallow để chặn bot truy cập trang, bot sẽ không thể đọc nội dung trang để thấy lệnh Noindex. Do đó, việc dùng Noindex trên trang bị Disallow sẽ không ngăn được bot lập chỉ mục trang đó.
Việc hiểu rõ robots.txt là gì và cách sử dụng đúng file này sẽ giúp bạn kiểm soát hiệu quả việc thu thập dữ liệu trên website, nâng cao hiệu quả SEO và bảo vệ các nội dung quan trọng. Áp dụng đúng quy tắc trong robots.txt không chỉ giúp các công cụ tìm kiếm hoạt động thuận lợi mà còn góp phần cải thiện trải nghiệm người dùng trên trang của bạn.
Thông tin liên hệ:
- Địa chỉ: Số 48 đường T17, dự án KDC & CV Phước Thiện (Khu C) tại số 88, đường Phước Thiện, khu phố Phước Thiện, P. Long Bình, TP. Thủ Đức, TP. HCM, Việt Nam
- Hotline: 1900.888.842
- Email: [email protected]
- Website: https://cyno.com.vn/